Synthetische Daten – Künstliche Daten für die digitale Zukunft?
Synthetische Daten – Künstliche Daten für die digitale Zukunft?
Weitere Erklärungen befinden sich in den ergänzenden Folien.
Es ist absehbar, dass Politik und Verwaltung zukünftig stärker auf Daten aus verschiedensten Quellen angewiesen sein werden, um evidenzbasiert und wirkungsvoll handeln zu können. Diese unabdingbaren Daten sind häufig schutzbedürftig, zum Beispiel wenn sie Personenbezüge, Geschäftsgeheimnisse oder sicherheitsrelevante Informationen enthalten. Mit steigender Anzahl von Daten für die verschiedensten Zwecke sowie bei der Nutzung in unterschiedlichen Bereichen erhöht sich das Risiko, unbeabsichtigt schutzbedürftige Informationen aufzudecken. Im Zuge des Trends zu Open Data und transparentem Verwaltungshandeln scheint es sinnvoller, bereinigte (anonymisierte) und verteilbare Daten bereitzuhalten oder kurzfristig über automatisierte Verfahren zu erstellen, als individuelle Zusammenstellungen schutzbedürftiger Verwaltungsdaten im Einzelfall auf mögliche Risiken zu überprüfen.
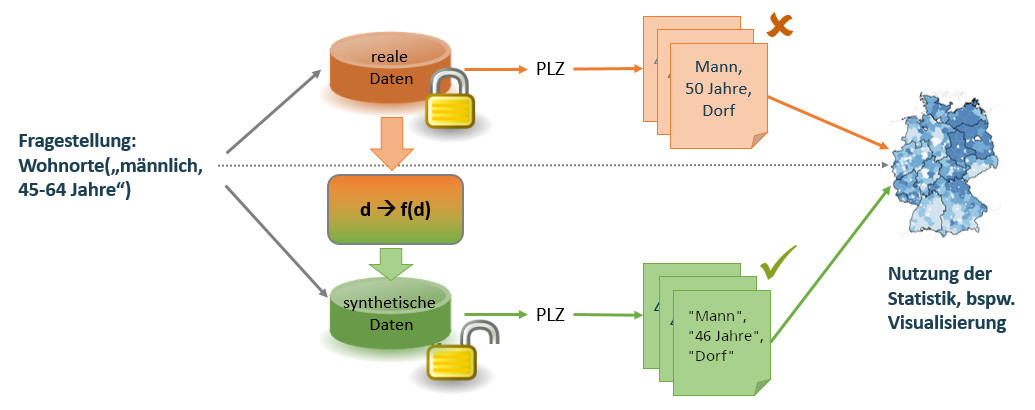
Eine erfolgversprechende und in ersten Anwendungsgebieten bereits eingesetzte Methodik ist die Erzeugung von synthetischen Daten. Synthetische Daten sind »künstliche« Daten, die in Eigenschaften und Struktur (idealerweise) den Originaldaten stark ähnlich sind, selbst aber keine »echten« Datenpunkte enthalten. Synthetische Daten werden aus Originaldaten generiert, indem ein mathematisches Modell trainiert wird, das die Struktur der ursprünglichen Daten lernt und reproduzieren kann. Synthetische Daten und Originaldaten sollten daher bei einer statistischen Analyse sehr ähnliche Ergebnisse liefern.
Synthetische Daten können außerdem perspektivisch für das Training von KI-Anwendungen in der öffentlichen Verwaltung von Bedeutung sein, da KI-Verfahren teilweise große Mengen an Trainings- und Testdaten benötigen. Dabei müssen die darin enthaltenen Informationen sorgfältig kontrolliert werden, beispielsweise in Bezug auf die Vermeidung von Diskriminierung. Ein weiteres Anwendung-Szenario findet sich in Fällen, wo die Datenmenge für das Training zu klein ist und durch synthetische Daten angereichert werden muss.
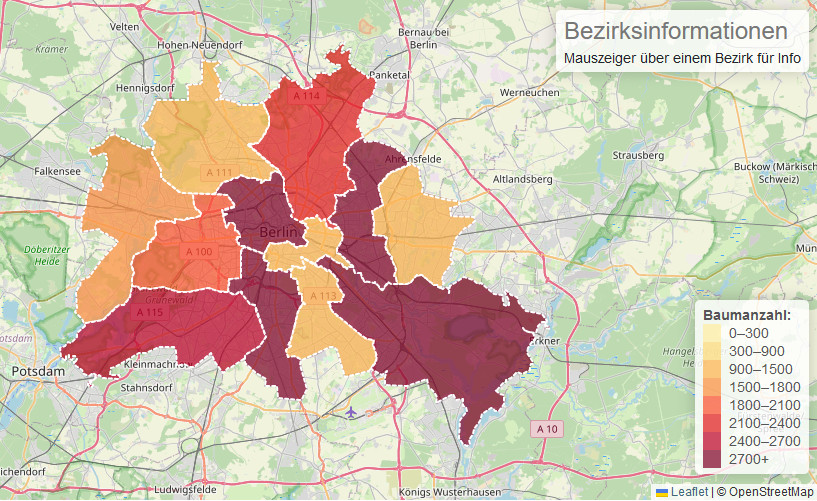
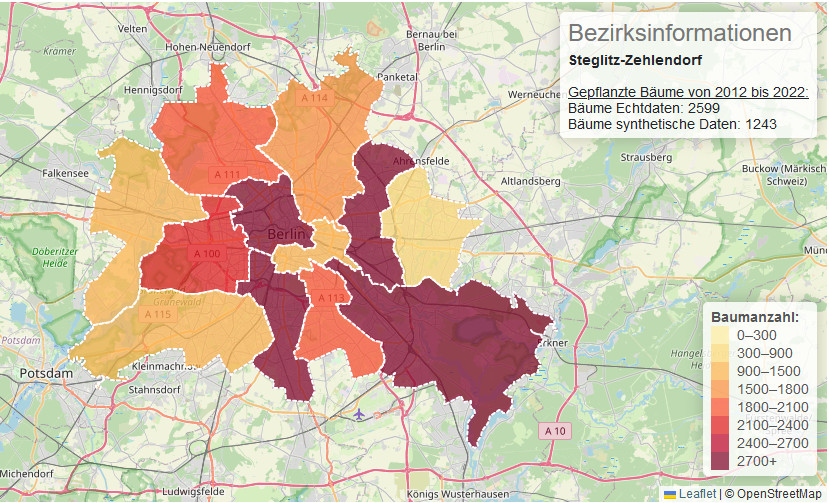
Der Demonstrator Synthetische Daten ist dafür gedacht, Interessierten aus Politik wie Zivilgesellschaft einen einfachen Zugang zu dem komplexen Themenfeld synthetische Daten zu ermöglichen. Anhand von einem Beispieldatensatz (Stadtbäume Berlin) werden ausgewählte Methoden zur Generierung von Daten miteinander verglichen. Die interaktive Anwendung macht die Eigenschaften der (synthetischen) Daten greifbar und erlaubt eine konkrete Anschauung zu ihren Möglichkeiten und Limitationen. Wichtig ist, dass es nicht die eine »beste« Methode gibt. Stattdessen ist je nach Anwendungsfall die Methodik zur Generierung gegebenenfalls anzupassen, wobei insbesondere die Struktur der Daten, die statistischen Eigenschaften sowie der gewünschte Outcome berücksichtigt werden sollten.
Eine wichtige Frage bei der Handhabung von Daten ist die der Qualitätssicherung. Was bedeutet das im Kontext synthetischer Daten? Wenn es sich um visuelle Daten handelt (Bilder oder Geokoordinaten aus dem Demonstrator-Beispiel) hilft oft schon eine Darstellung der Daten, um offensichtliche Qualitätsmängel festzustellen. Bei den hier präsentierten Methoden finden sich Qualitätsunterschiede in der Genauigkeit, mit der die statistischen Eigenschaften der Ausgangsdaten in den erzeugten Daten repliziert wurden. Solche Erkenntnisse können bei der Wahl einer geeigneten Methode herangezogen werden.
Eine andere Methode zur Messung der Qualität ist der Vergleich der Performanz von Neuronalen Netzen, die einmal mit Originaldaten und einmal mit synthetischen Daten trainiert werden. Eine solche Bewertung ist in Abbildung 4 zu sehen (MLP Classifier). In diesem Fall wurde ein Neuronales Netz darauf trainiert, das Alter von Bäumen anhand der Größe, des Umfangs und des Ortes zu bestimmen. Je höher der Wert, desto besser sind die Vorhersagen. Um die Qualität der synthetischen Daten einzuschätzen, wird der Score relativ zu dem der realen Daten betrachtet.
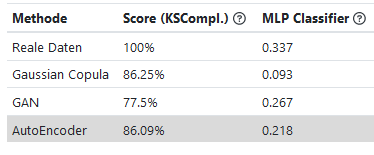
Abschließend ist festzustellen, dass synthetische Daten statistische Eigenschaften der Realdaten nie perfekt abbilden. Dies muss jedoch nicht unbedingt ein Problem sein. Wichtig ist, die Daten im Hinblick auf das geplante Anwendungsszenario zu bewerten. Insbesondere bei der Nutzung von sensiblen Daten kann es vorteilhaft sein, meist unbedenklichere synthetische Daten zu verwenden und dafür leichte Performanceeinbußen hinzunehmen.
Für einen einfachen Einstieg in das komplexe Themenfeld und den Demonstrator steht ein Foliensatz zur Verfügung. In diesem sind die verwendeten Daten, Methoden und Zugänge zum Demonstrator auf verständliche Art aufbereitet:
Link zu den Folien
Was zeigt der Demonstrator?
1. Synthetische Daten sind nicht gleich synthetische Daten.
Nützlich sind synthetische Daten dann, wenn sie gewisse statistische Eigenschaften abbilden, die auch in den Originaldaten zu finden sind. Das heißt, sie sollten insbesondere in Bezug auf im Mittelpunkt des Interesses stehende Eigenschaften möglichst »ähnlich« sein. Was das bedeutet, ist jedoch nicht unbedingt eindeutig zu bestimmen. Unterschiedliche Methoden zur Generierung der synthetischen Daten führen zu unterschiedlich guter Abbildung abhängig von der angewandten Vergleichsmetrik.
2. Synthetische Daten können unter Umständen Daten als Alternative zu herkömmlichen Anonymisierungsmethoden genutzt werden.
Anonymisiert werden müssen Daten dann, wenn sie sensible Informationen enthalten, die Rückschlüsse auf Individuen zulassen. Unter Umständen werden Daten aufgrund von Bedenken zu Daten- oder Geheimschutz gar nicht erst veröffentlicht. Offene Daten sind jedoch nicht nur für Forschung elementar wichtig. Eine Möglichkeit könnte sein, statt der Originaldaten entweder eine synthetische Datenbasis zu veröffentlichen, die »ausreichend genau« die statistischen Eigenschaften der Originaldaten abbilden oder direkt die Funktion zur Generierung solcher Daten.
3. Die »Qualität« synthetischer Daten ist nicht ohne Weiteres bestimmbar und Anwendung bleibt herausfordernd.
Was »Qualität« im Kontext synthetischer Daten bedeutet, ist nicht klar definiert. Existieren darüber hinaus Verzerrungen (Bias) in den Originaldaten, werden sich diese wahrscheinlich auch in den synthetischen Daten wiederfinden. Der Versuch, synthetische Daten zu nutzen, um Originaldaten zugunsten von Fairness-Aspekten zu manipulieren, führt ggf. zu inkorrekten Daten.
4. Die Potentiale synthetischer Daten sind groß.
Verstärkte Forschung und Entwicklung praktischer, leicht zugänglicher Anwendungen in dem Themenfeld kann ermöglichen, die derzeitigen Herausforderungen mit synthetischen Daten zu adressieren. Sollen synthetische Daten als Alternative zu dem herkömmlichen Anonymisieren dienen, müssen Methoden gefunden werden, die sicherstellen, dass keine sensiblen Informationen aus den synthetischen Daten extrahiert werden können (Information Leak).
Weitere Erklärungen befinden sich in den ergänzenden Folien.
Weiterführendes von ÖFIT:
September 2022
Die Logik der Daten nutzen - Fortschrittliche Datenstrategien entwickeln
Daten bieten perfekte Eigenschaften für eine intensive Nutzung: Sie nutzen sich nicht ab und schaffen mitunter völlig neue Lösungsmöglichkeiten. Entsprechend bedeutsam für Staat, Gesellschaft und Wirtschaft ist es, dass Daten möglichst vielfältig genutzten werden. Bislang profitieren jedoch nur wenige Akteure von meist eigenen, geschlossenen Datenquellen. Datenstrategien sollten, so das Petitum dieses White Papers, dies berücksichtigen und als umfassende Datennutzungsstrategien angelegt werden. Dabei rückt die Frage in den Mittelpunkt, wie die Datenteilung und -nutzung incentiviert und Barrieren abgebaut werden können. Ziel ist es, den Wettbewerb um die besten, datengetriebenen Ideen zu eröffnen und so Innovationen zu fördern.
Zur PublikationDezember 2020
KI im Behördeneinsatz - Erfahrungen und Empfehlungen
Mit künstlicher Intelligenz (KI) verbinden sich große Erwartungen ebenso wie Skepsis und tiefsitzende Befürchtungen – gerade auch beim Einsatz in der öffentlichen Verwaltung. Um hier die richtigen Rahmenbedingungen zu schaffen, wurden in den letzten Jahren weltweit zahlreiche Leitlinien erarbeitet. Inwiefern werden diese Vorgaben beim KI-Einsatz in der deutschen öffentlichen Verwaltung berücksichtigt? Für die Studie wurden Fallbeispiele aus allen Bereichen der öffentlichen Leistungserbringung auf Bund-, Länder- und Kommunenebene analysiert. Entstanden ist eine systematische Bewertung der KI-Landschaft in der deutschen Verwaltung, die viele praktische Hinweise liefert, wie der KI-Einsatz unter den besonderen Erfordernissen der öffentlichen Verwaltung gelingend gestaltet werden kann.
Zur PublikationVeröffentlicht: 25.05.2023